
High availability in data centres refers to the ability of IT systems and infrastructure to remain operational and accessible with minimal interruption, typically measured as a percentage of uptime over a given period. Industry leaders target 99.99% (“four nines”) or higher availability, equating to less than 52 minutes of unplanned downtime annually.
Achieving this level requires deliberate design incorporating tier classifications, redundancy models, failover mechanisms, and proactive reliability engineering practices.
These elements collectively eliminate or mitigate single points of failure across power, cooling, networking, and compute systems.
Uptime Institute Tier Classifications
The Uptime Institute provides the most widely recognised framework for classifying data centre reliability through four tiers, each defining progressively higher levels of fault tolerance and expected availability.
- Tier I: Basic capacity with a single path for power and cooling. No redundancy. Expected availability: ~99.671% (28.8 hours of downtime per year).
- Tier II: Redundant components (N+1) but still a single distribution path. Maintenance requires shutdown. Expected availability: ~99.741% (22 hours downtime per year).
- Tier III: Concurrently maintainable. Multiple independent distribution paths with N+1 redundancy. One path can be taken offline for maintenance without affecting operations. Expected availability: ~99.982% (1.6 hours downtime per year).
- Tier IV: Fault tolerant. Fully fault-tolerant with multiple independent, active distribution paths and 2N (or higher) redundancy. Can withstand any single unplanned failure without impact. Expected availability: ~99.995% (0.4 hours downtime per year).
Certification requires rigorous design review, construction observation, and operational sustainability demonstration.

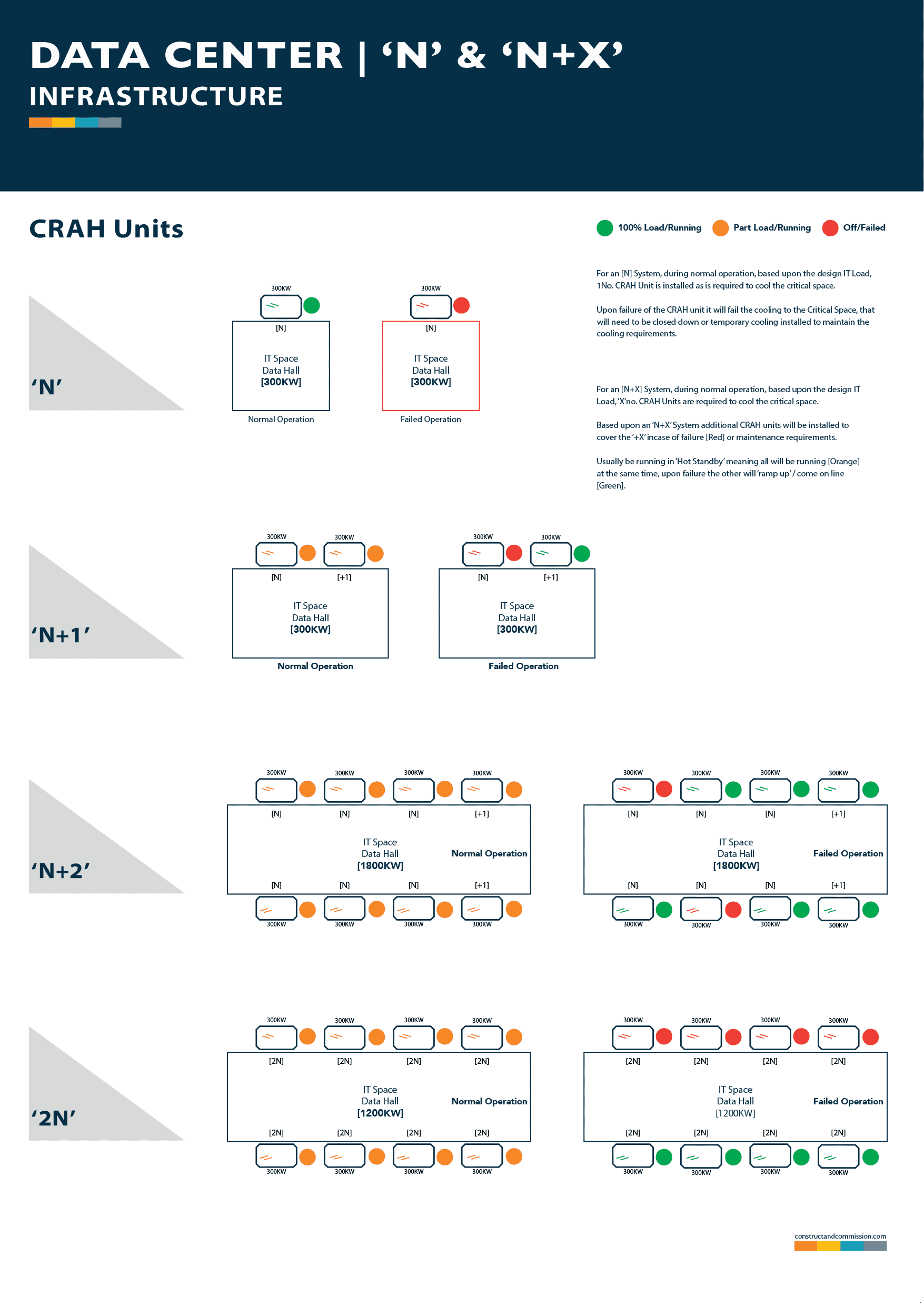
Redundancy Models: N+1 and 2N
Redundancy eliminates dependence on any single component by providing backup capacity or paths.
- N+1 Redundancy: Provides one additional unit beyond the minimum required (N) to meet load. For example, if five cooling units are needed, six are installed. This protects against the failure of one component but does not allow full concurrent maintainability without risk.
- 2N Redundancy: Duplicates the entire required capacity (N) with a second, independent set (another N). Two completely separate power and cooling systems operate in parallel. This model supports fault tolerance, as the loss of one entire path leaves full capacity intact.
READ ALSO:The Essential Components of a Modern Data Centre
Higher configurations (e.g., 2N+1 or 3N) further enhance resilience for hyperscale or mission-critical environments.
Failover Strategies
Failover ensures seamless transition to backup systems when primary components fail or are taken offline.
Common mechanisms include:
- Automatic Transfer Switches (ATS): Detect utility power loss and switch to generator or alternate feed within milliseconds to seconds.
- Static Transfer Switches (STS): Provide sub-cycle (sub-4 ms) switching between two independent power sources.
- UPS Battery Bridging: Instantaneous battery discharge covers the gap until generators start (typically 10–60 seconds).
- Network Failover: Protocols such as VRRP, BGP, or SDN-based routing redirect traffic to alternate paths or facilities in seconds.
- Application-Level Failover: Load balancers, database replication (synchronous/asynchronous), and multi-region cloud architectures distribute workloads across zones.
These strategies are tested regularly through simulated failure drills to validate response times and recovery procedures.
Reliability Engineering Practices
Beyond hardware redundancy, modern data centres employ systematic engineering to maximise uptime:
- Predictive Maintenance: Continuous monitoring of temperature, vibration, power quality, and component health using sensors and AI-driven analytics to identify degradation before failure.
- Capacity Planning and Load Management: Dynamic adjustment of workloads to prevent overload on any single path.
- Change Management: Strict procedures for updates, patches, and configuration changes to avoid human-induced outages.
- Geographic Dispersion: Multi-site replication and disaster recovery planning to protect against regional events (floods, earthquakes, grid failures).
- Metrics and SLAs: Tracking Mean Time Between Failures (MTBF), Mean Time to Repair (MTTR), and Power Usage Effectiveness (PUE) alongside formal availability commitments.
Data centres achieve high availability and exceptional uptime through a combination of tiered design standards, strategic redundancy models (N+1 and 2N), automated failover mechanisms, and disciplined reliability engineering.
These layered defences ensure that critical digital services remain accessible even under adverse conditions.
For organisations evaluating or operating data centre infrastructure, alignment with recognised tier classifications and rigorous testing of failover scenarios remain essential to meeting demanding service-level objectives.
Ronnie Paul is a seasoned writer and analyst with a prolific portfolio of over 1,000 published articles, specialising in fintech, cryptocurrency, climate change, and digital finance at Africa Digest News.





Leave a Reply